
MySQL基础
数据库原理与应用基础
通用语法
- SQL语句可以单行或者多行书写,英文状态,以分号结尾;
- 不区分大小写,关键字建议用大写
- 注释:
- 单行注释: – 注释内容 或者 # 注释内容
- 多行注释:/* 注释内容 */
SQL分类
| 分类 | 说明 |
|---|---|
| DDL | 数据定义语言,用来定义数据库对象(数据库、表、字段) |
| DML | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | 数据查询语言,用来查询数据库中表的记录 |
| DCL | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
DDL——数据定义语言
| 数据库操作 功能 | 指令 | |
|---|---|---|
| 查询所有数据库 | show databases; | |
| 查询当前所处的数据库 | select database(); | |
| 创建 | create database [if not exists] 数据库名 [default charset 字符集类型]; | 字符集:utf8 [mb4] (三 / 四个字节 |
| 删除 | drop database [if exists] 数据库名; | |
| 使用 | use 数据库名; |
| 表 操作——查询 | 指令 |
|---|---|
| 查询当前数据库所有表 | show tables; |
| 查询表结构 | desc 表名; |
| 查询指定表的建表语句(详细 | show create table 表名; |
DDL—表操作——创建
create table 表名(
字段1 字段1类型 [约束] [comment 字段1 注释],
字段2 字段2类型 [约束] [comment 字段2 注释],
… …
字段n 字段n类型 [约束] [comment 字段n 注释]
) [comment 表注释] ;
MySQL数据类型
| 数值类型 | 类型 | 描述 | 大小 | |
|---|---|---|---|---|
| tinyint | 极小整数值 | 1 byte | ||
| smallint | 小整数值 | 2 byte | ||
| int或者integer | 整数型 | 4 byte | ||
| bigint | 大整数值 | 8 byte | ||
| float | 浮点 | 4 byte | ||
| double | 长浮点 | 8 byte | ||
| decimal | 小数值(精确定点数 | |||
| 字符类型 | char() | 定长字符串 | ||
| varchar() | 可变长字符串 | |||
| blob | 二进制形式的长文本数据 | |||
| text | 长文本数据 |
| 分类 | 类型 | 描述 | 范围 | 格式 | 大小 |
|---|---|---|---|---|---|
| 日期类型 | DATE | 日期值 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 3 |
| TIME | 时间值或持续时间 | -838 :59 :59 至 838 :59 :59 | HH : MM : SS | 3 | |
| YEAR | 年份值 | 1901 至 2155 | YYYY | 1 | |
| datetime | 混合日期和时间值 | 1000-01-01 00 : 00 : 00 至 9999-12-31 23 : 59 : 59 | YYYY-MM-DD HH : MM : SS | 8 | |
| timestamp | 混合日期和时间值、时间戳 | 1970-01-01 00 : 00 : 01 至 2038-01-19 03 : 14 : 07 | YYYY-MM-DD HH : MM : SS | 4 |
DDL—表操作——修改
| 功能 | 语法格式 | 注意 |
|---|---|---|
| 添加字段 | Alter table 表名 add 字段名 类型(长度) [comment注释] [约束]; | |
| 修改数据类型 | Alter table 表名 modify 字段名 新数据类型(长度); | |
| 修改字段名和字段类型 | Alter table 表名 change 旧字段名 新字段名 类型(长度) [注释] [约束]; | |
| 删除字段 | Alter table 表名 drop 字段名; | |
| 修改表名 | Alter table 表名 rename to 新表名; |
DDL—表操作——删除
| 功能 | 语法格式 | 注意 |
|---|---|---|
| 删除表 | drop table [if exists] 表名; | 表的数据也全部被删除 |
| 删除指定表,并重新创建该表 | truncate table 表名; | 会把表结构删除,重新创建一个表 |
DML——表的数据记录进行增删改操作
DML—添加数据
| 功能 | 语法格式 | 注意 |
|---|---|---|
| 给指定字段添加数据 | insert into 表名 ( 字段名1,字段名2,…) values (值1 , 值2,…); | 一次插入一条数据 |
| 给全部字段添加数据 | insert into 表名 values ( 值1,值2,…); | 一次插入一条数据,一一对应字段顺序添加 |
| 批量添加数据 | 1. insert into 表名 ( 字段名1,字段名2,…) values (值1 , 值2,…) , (值1 , 值2,…) , (值1 , 值2,…) ; | 一次多条, |
| 2. insert into 表名 values ( 值1,值2,…) , ( 值1,值2,…) , ( 值1,值2,…) ; |
注意:
- 插入数据 时一一对应字段和值的顺序
- 字符串和日期型数据应该包含在引号中
- 插入的数据大小,应该在字段的规定范围内
DML—修改数据
| 功能 | 语法格式 | 注意 |
|---|---|---|
| 修改字段 | update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , …[where 条件] ; | 如果要求修改同一字段所有值,不用where条件 |
DML—删除数据
| 功能 | 语法格式 | 注意 |
|---|---|---|
| 删除数据 | delete from 表名 [where 条件] | 条件可有可无,delete语句不能删除某一个字段的值(可以使用update修改) |
DQL—*查询语言

create table staffinfo
(
id int,
workno char(9),
name char(9),
sex char(2),
age tinyint unsigned,
idcard char(18),
workaddress varchar(50),
entrydate date
)comment '员工信息表';
insert into staffinfo (id,workno,name,sex,age,idcard,workaddress,entrydate)
values (1,'1','柳岩','女',20,'123456789012345678','北京','2000-01-01'),
(2,'2','张无忌','男',18,'123456789012345670','北京','2002-09-01'),
(3,'3','韦一笑','男',19,'123456789012345671','上海','2005-08-01'),
(4,'4','赵敏','女',22,'123456789012345672','北京','2001-12-01'),
(5,'5','小昭','女',16,'123456789012345673','上海','2007-07-01'),
(6,'6','杨逍','男',28,'12345678901234567X','北京','2006-01-01'),
(7,'7','范瑶','男',40,'123456789012345670','北京','2005-05-01'),
(8,'8','黛绮丝','女',38,'123456789012345675','天津','2015-05-01'),
(9,'9','范凉凉','女',45,'123456789012345674','北京','2010-04-01'),
(10,'10','陈友谅','男',53,'123456789012345676','上海','2011-01-01'),
(11,'11','张士诚','男',55,'123456789012345668','江苏','2015-05-01'),
(12,'12','常遇春','男',32,'123456789012345661','北京','2004-02-01'),
(13,'13','张三丰','男',68,'123456789012345658','江苏','2020-11-01'),
(14,'14','灭绝','女',65,'123456789012345654','西安','2019-05-01'),
(15,'15','胡青牛','男',47,'123456789012345628','西安','2018-01-01'),
(16,'16','周芷若','女',18,null,'北京','2012-06-01');基本查询
1.查询多个字段
select 字段1,字段2,字段3 ... from 表名; //查询多个
select * from 表名; //查询全部
2.设置别名
select 字段1 [AS 别名1],字段2[AS 别名2] ... from 表名; // AS可以省略
3.去除重复记录
select distinct 字段1,... from 表名;
条件查询(where)
语法格式:
select 字段列表 from 表名 where 条件列表;条件
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| * <> 或 != | 不等于 |
| * between … and … | 在某个范围之内(含最小、最大值) |
| in( ) 或 not in( ) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单个字符,%匹配任意个字符) |
| is null | 是 null |
| 逻辑运算符 | 功能 |
|---|---|
| and 或者 && | 并且(多个条件同时成立) |
| or 或者 || | 或者(多个条件任意一个成立) |
| not 或者 ! | 非,不是 |
1.查询年龄等于 88 的员工
select * from staffinfo where ago = 88;
2.查询没有身份证号的员工信息
select * from staffinfo where idcard is null;
3.查询有身份证号的员工信息
select * from staffinfo where idcard is not null;
4.查询年龄在15岁(包含)到20岁(包含)之间的员工信息
select * from staffinfo where age >=15 && age <=20;
select * from staffinfo where age >=15 and age <=20;
select * from staffinfo where age between 15 and 20; -- 15跟20不能换位置
5.查询姓名为两个字的员工信息
select * from staffinfo where name like '__'; -- 两个占位符
6.查询身份证号最后一位是X的员工信息
select * from staffinfo where idcard like '%X'; -- X前面有多少个字符都不影响
聚合函数——纵向计算
语法格式:
select 聚合函数(字段列表) from 表名;| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
1.统计该企业的员工数量
select count(id) from staffinfo;
2.统计西安地区员工的年龄之和
select sum(age) from staffinfo where workaddress = '西安';注意:null值不参与所有聚合函数运算
分组查询(group by)
语法格式
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];where 与 having 区别
- 执行时机不同:where是分组之前进行过滤的,不满足where条件,不参与分组;而having 是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以
- 搭配:有group by 才能使用 having
1.根据性别分组,统计男性员工 和 女性员工的数量
select sex,count(id) from staffinfo group by sex;
2.查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
-- 先查询数量和分组 后面having接获取
select workaddress,count(*) from staffinfo where age < 45 group by workaddress having count(*) >= 3;注意:
- 执行顺序:where > 聚合函数 > having
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
排序查询(order by)
语法格式
select 字段列表 from 表名 order by 字段1 排序方式1, 字段2 排序方式2;排序方式:ASC 升序(默认) DESC 降序
1.根据年龄对公司的员工进行升序排序
select * from staffinfo order by age;
select * from staffinfo order by age desc; -- 降序要加desc 升序可省略
2.根据年龄对公司的员工进行升序排序,年龄相同,再按照入职时间进行降序排序
select * from staffinfo order by age , entrydate desc;注意:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
分页查询(limit)
语法格式
select 字段列表 from 表名 limit 起始索引,查询记录数;注意:
- 起始索引从 0 开始,起始索引 = (查询页码 - 1) * 每页显示记录数。
- 不同数据库不同实现分页查询功能
- 如果查询的是第一页数据,起始索引可以省略,直接简写为limit 10。
1.查询第1页员工数据,每页展示10条记录
select * from staffinfo limit 0,10;
select * from staffinfo limit 10; -- limit默认从0页开始
2.查询第2页员工数据,每页展示10条记录
-- (页码-1)* 页展示记录数
select * from staffinfo limit 10,10;练习——in 和 like 用法注意
1.查询年龄为20,21,22,23岁的女性员工信息。
select * from staffinfo where age<=23 && age>=20 && sex='女';
select * from staffinfo where sex = '女'and age in(20,21,22,23);
*2.查询性别为男,并且年龄在20--40岁(含)以内的姓名为三个字的员工
select * from staffinfo where sex = '男' && age <=40 && age >=20 && name like '___';
3.统计员工表中,年龄小于60岁的,男性员工和女性员工的人数。
select sex,count(id) from staffinfo where age<60 group by sex;
4.查询所有年龄小于等于35岁员工的姓名和年龄,并对查询结果按年龄升序排序,如果年龄相同暗入职时间降序排序
select name,age from staffinfo where age <= 35 order by age,entrydate desc;
5.查询性别为男,且年龄在20--40岁(含)以内的前5个员工信息,对查询的结果按年龄升序排序,年龄相同按入职时间升序排序
select * from staffinfo where sex = '男' && age<=40 && age>=20 order by age,entrydate desc limit 5;DCL——数据控制语言
函数
字符串函数
| 函数 | 功能 |
|---|---|
| concat(s1 , s2 , … sn) | 字符串拼接,将s1,s2,… sn拼接成一个字符串 |
| lower(str) | 将字符串str 全部转换为小写 |
| upper(str) | 将字符串str 全部转换为大写 |
| lpad(str,n,pad) | 左填充,用字符串pad对str的左边进行填充,达到n个字符串长度 |
| rpad(str,n,pad) | 右填充,用字符串pad对str的右边进行填充,达到n个字符串长度 |
| trim(str) | 去掉字符串头部和尾部的空格 |
| substring(str,start,len) | 返回字符串str从start位置起的len个长度的字符串 |
select concat('Hello','MySQL');
-- HelloMySQL
select lower(HEllo);
-- hello
select upper(HEllo);
-- HELLO
select lpad('01',5,'-');
-- ---01
select rpad('01',5,'-');
-- 01---
select trim(' Hello MySQL ');
-- Hello MySQL
select substring('Hello MySQL',1,5)
-- Hello例
1.企业员工的工号,统一为5位数,目前不足为5位数的全部在前面补0.比如:1号工号应该为00001.
update staffinfo set workno = lpad(workno,5,'0');数值函数
| 函数 | 功能 |
|---|---|
| ceil(x) | 向上取整 |
| floor(x) | 向下取整 |
| mod(x,y) | 返回x / y 的模 求余数 |
| rand() | 返回0~1内的随机数 |
| round(x,y) | 求参数x的四舍五入的值,保留y位小数 |
案例:通过数据库的函数,生成一个六位数的随机验证码
select lpad(round(rand() * 1000000,0),6,'0');日期函数
| 函数 | 功能 |
|---|---|
| curdate( ) | 返回当前日期 |
| curtime( ) | 返回当前时间 |
| now( ) | 返回当前日期和时间 |
| year(date) | 获取指定date的年份 |
| month(date) | 获取指定date的月份 |
| day(date) | 获取指定date的日期 |
| date_add(date,interval expr type) | 返回一个日期/时间值加上一个时间间隔expr后的时间值 |
| datediff(date1 , date2) | 返回起始时间date1和结束时间date2之间的天数 |
select concat('已经在地球上存活了 ',datediff('2023-11-04','2003-11-04'),' 天');
select date_add(now(),INTERVAL 70 date); -- 返回70天之后的时间
案例:查询所有员工的入职天数,并根据入职天数倒序排序
select name,datediff(curdate(),entrudate) as 'entrydates' from emp order by entrydays desc;*流程函数
| 函数 | 功能 |
|---|---|
| IF(value(条件表达式) , t ,f ) | 如果value为TRUE ,则返回t,否则返回f |
| ifnull( value1 , value2) | 如果value1 不为空,返回value1,否则返回value2 |
| Case when [val1] then [resl1] … else [default] end | 如果val1为TRUE,返回res1,… 否则返回default默认值 |
| Case [expr] when [val1] then [resl1] … else [default] end | 如果expr 的值等于val1,返回res1,… 否则返回default默认值 |
1.if
select if(true,'ok','error'); -- ok
select if(false,'ok','error'); -- error
2.ifnull
select ifnull(null,'default'); -- 空,返回default
3.需求:查询staffinfo表的员工姓名和工作地址(北京/上海 ----> 一线城市,其他------> 二线城市)
select name ,if (workaddress in('北京', '上海'),'一线城市','二线城市') from staffinfo;
select name,if (workaddress = '北京' or workaddress = '上海','一线城市','二线城市') from staffinfo;
select name,
(case workaddress when '北京' then '一线城市' when '上海' then '一线城市' else '二线城市' end) as '工作地址'
from staffinfo;案例:统计班级各个学员的成绩,展示规则如下
---->=85 优秀
---->=60 及格
----否则 不及格
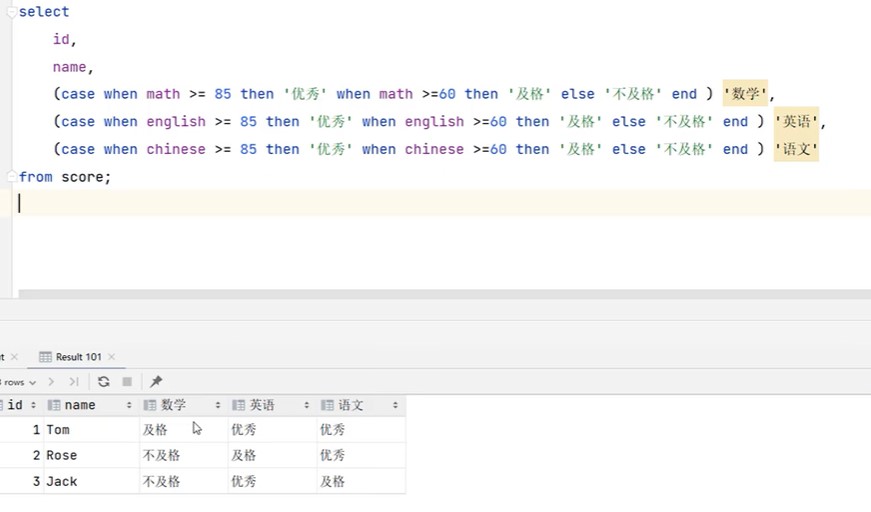
约束
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制字段数据不能为null | not null |
| 唯一约束 | 保证该字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | primary key |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | default |
| 检查约束 | 保证字段值满足某一个条件 | check |
| 外键约束 | 用来让两张表的数据之间建立连接,保证数据的一致性和完整性 | foreign key from哪个表 |
约束案例
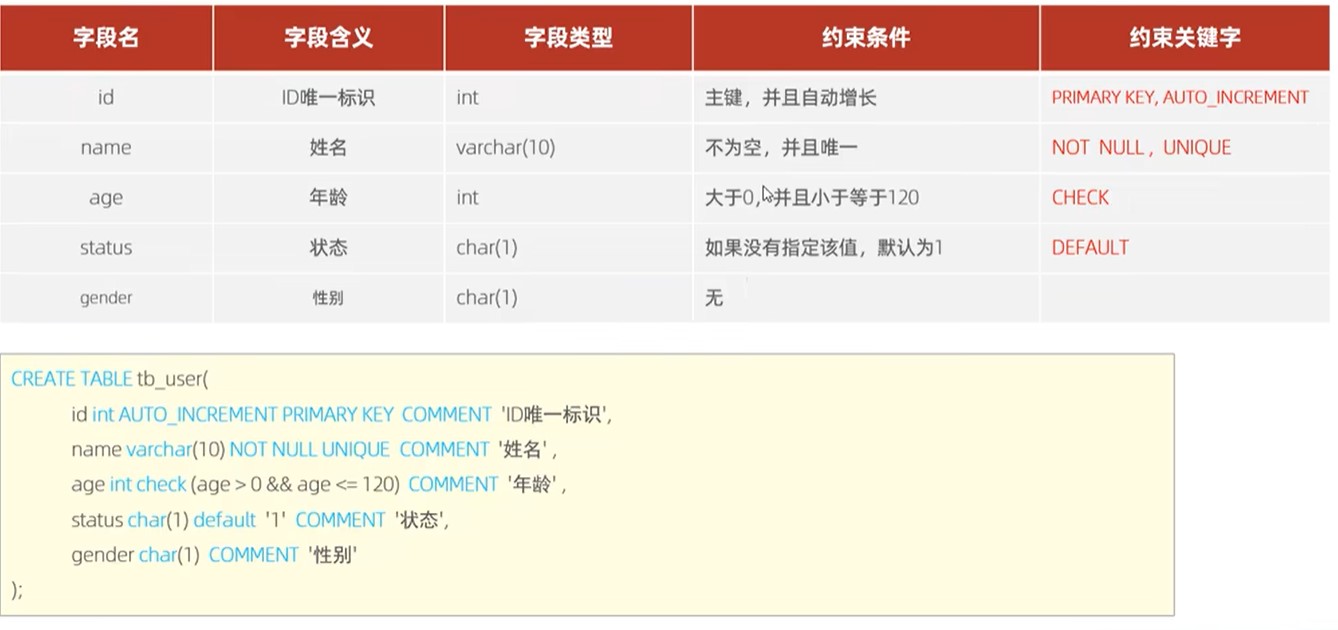
外键约束
语法格式
1.添加外键
create table 表名(
字段名 数据类型,
...
[constraint] [外键名称] foreign key (外键字段名) references 外表(外表列名)
);
2.删除外键
alter table 表名 drop foreign key 外键名称;*多表查询
三种关系
- 一对多(多对一)
- 多对多
- 一对一
概述
-
连接查询
- 内连接:相当于查询A、B交集部分
- 外连接:
- 左外连接:查询左表所有数据,以及两张表交集部分数据
- 右外连接:查询右表所有数据,以及两张表交集部分数据
- 自连接:当前表与自身的连接查询,自连接必须使用表别名
-
子查询

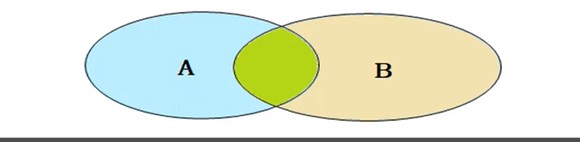
连接查询——内连接
查询语法
1.隐式内连接
select 字段列表 from 表1,表2 where 条件...;
2.显式内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件...; (inner 可省略)示例
1.查询每一个员工的姓名,及关联的部门的名称(隐式内连接实现)
-- 表结构:emp , dept
-- 连接条件:emp.dept_id = dept.id
select emp.name , dept.name from emp,dept where emp.dept_id = dept.id;
-- 给表起别名,起别名之后只能用别名
select e.name,d.name from emp e,dept d where e.dept_id = d.id;
2.显式内连接实现 inner join ... on ...
select e.name,d.name from emp e inner join dept d on e.dept_id = d.id;进阶
存储过程的规划与设计
概念
存储过程 是一组为了完成特定功能的SQL语句集,编译后以一个名称存储在数据库中,可以避免重复编写相同的sql语句,而且存储过程是在MySQL服务器中存储和执行的,可以减少客户端和服务器端的数据传输。
优点:提高执行速度;像函数可将复杂操作存储过程封装起来,与数据库提供的事务处理结合一起使用;可以重复利用,安全高效。
存储过程分,无参和有参
1.创建一个无参的存储过程good_
DELIMITER $$ -- 设定$$为结束符号
create procedure stu_info() -- 创建过程 名字为stu_info
begin
select * from student; -- 分号不是结束符
end$$ -- 这个才是结束符
DELIMITER ; -- 将结束符改回 ;
CALL stu_info(); -- 调用 存储过程
drop procedure stu_info; -- 删除之后才能重新create
2.创无参的stu_scourse,查过所有学生的个人信息和选课信息(要两个表的连接)
DELIMITER $$
create procedure stu_scourse()
begin
select * from student stu,scourse sco where stu.sid = sco.sid;
end$$
DELIMITER ;
CALL stu_scourse();*有参
有参:in 参数名(字符类型)—>输入参数 out 参数名(字符类型)—>输出参数
1.创建一个带有输入参数的
DELIMITER $$
create procedure pro_qbybid(in bid char(15)) -- bid 是一串字符编号
begin
select * from bookinfo where cbook = bid;
end $$
DELIMITER ;
CALL pro_qbybid('b1235');
2.创既有输出参又有输入参pro_qbybpub(),
DELIMITER $$
create procedure pro_qbybpub(in bpub char(15),OUT num int) -- bid 是一串字符编号
begin
select * from bookinfo where bpublish=bpub;
end $$
DELIMITER ;
call pro_qbybpub('清华大学出版社',@num);
select @num;练习
1.创建一个带有输入和输出参数的存储过程pro_countbydep,计算指定系部(计算机系)的总人数,
并且调用该存储过程,查看输出结果。
DELIMITER $$
create procedure pro_countbydep(IN dep varchar(15),OUT total int)
begin
select count(sid) into total from student where dept = dep;
end $$
DELIMITER ;
set @total := 0;
call pro_countbydep('计算机系',@total);
select @total;
2.创建一个带有输入和输出参数的存储过程pro_avgbycid,计算指定课程(C3)的平均分,
并且调用该存储过程,查看输出结果。
DELIMITER $$
create procedure pro_avgbycid(IN cid varchar(10),OUT avgscore float)
begin
select avg(score) into avgscore from scourse where cid=cid;
end $$
DELIMITER ;
call pro_avgbycid('C3',@avgscore);
select @avgscore;